
Dynamische Konvertierung der Tags in HTML
Wiederverwendbare Inhalte sind ein echtes Asset für Unternehmen. Bei PDFs stellt sich dabei schnell die Frage: Für welches Ausgabegerät eigentlich? Handy, Tablet, Desktop – und überall soll’s gut lesbar sein.
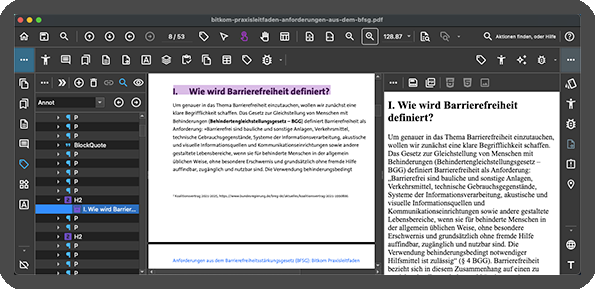
Abb. Screenshot von PDF Desktop mit einem Dokument als PDF oder HTML.
Die Idee einer „responsiven PDF“ führte vor einigen Jahren zu einem anderen Ansatz: Deriving HTML from PDF. Also PDFs, deren Inhalte sauber strukturiert und semantisch getaggt sind – sodass man die Inhalte aus den Tags bei Bedarf zuverlässig entnehmen und in HTML konvertieren kann.
Und genau hier wird barrierefreies PDF plötzlich zum Gamechanger: Wenn ein Dokument wirklich gut getaggt ist, kann es bei Bedarf in nahezu jede Darstellungsform überführt werden – passend für Screenreader, Mobile-Views, Web, Apps und interne Portale oder barrierefreier Gestaltung.
Kurz: „Responsive PDF“ als Layout-Eigenschaft ist schwierig – aber „responsive Nutzung“ ist möglich, wenn das PDF gut getaggt ist. Für die dynamische Extraktion und Wiederverwendung bieten SDKs wie das PDFix SDK die passenden Bausteine (Struktur auslesen, Inhalte extrahieren, Konvertierung/Export unterstützen).
Euskirchen, Februar 2026